IPython examples¶
Running Python code¶
Show Python version¶
[1]:
import sys
sys.version_info
[1]:
sys.version_info(major=3, minor=13, micro=0, releaselevel='final', serial=0)
Show versions of Python packages¶
Most Python packages provide a __version__ method for this:
[2]:
import pandas as pd
pd.__version__
[2]:
'2.2.3'
Alternatively, you can use version from importlib_metadata:
[3]:
from importlib.metadata import version
print(version("pandas"))
2.2.3
Information about the host operating system and the versions of installed Python packages¶
[4]:
pd.show_versions()
INSTALLED VERSIONS
------------------
commit : 0691c5cf90477d3503834d983f69350f250a6ff7
python : 3.13.0
python-bits : 64
OS : Darwin
OS-release : 24.6.0
Version : Darwin Kernel Version 24.6.0: Mon Jan 19 21:56:28 PST 2026; root:xnu-11417.140.69.708.3~1/RELEASE_ARM64_T6020
machine : arm64
processor : arm
byteorder : little
LC_ALL : None
LANG : None
LOCALE : None.UTF-8
pandas : 2.2.3
numpy : 2.0.2
pytz : 2024.2
dateutil : 2.9.0.post0
pip : None
…
Only use Python versions ≥ 3.9¶
[5]:
import sys
assert sys.version_info[:2] >= (3, 9)
Shell commands¶
[6]:
!python3 -V
Python 3.13.0
Tab completion¶
… for objects with methods and attributes:
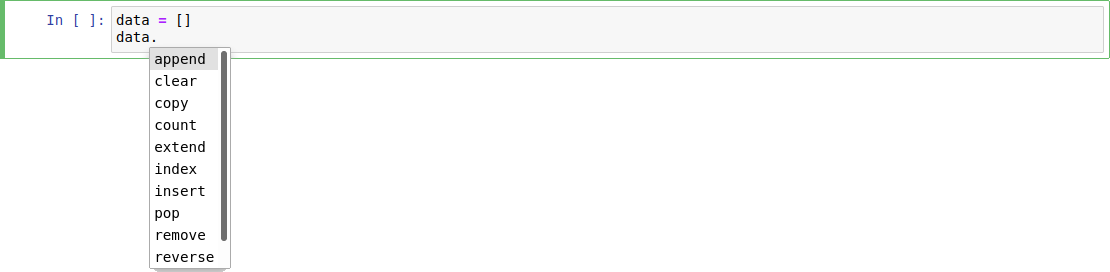
… and also for modules:
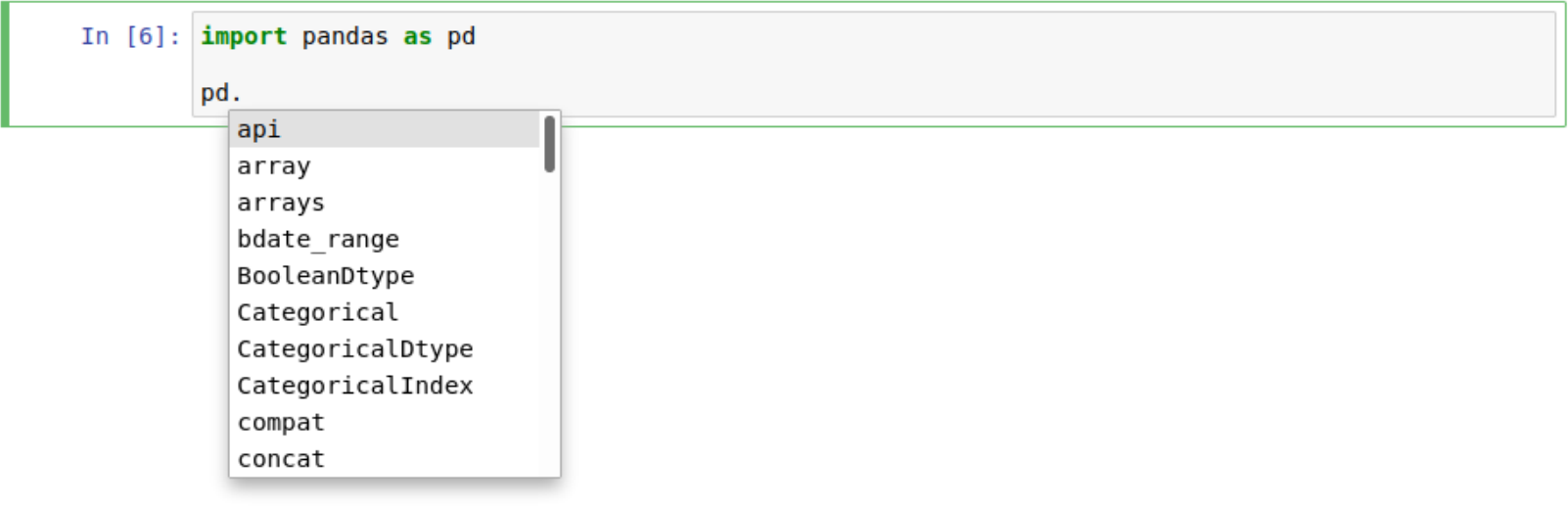
Note:
As you may have noticed in surprise, the __version__ method used above is not offered in the selection. IPython initially hides these private methods and attributes that begin with underscores. However, they can also be completed with a tabulator if you first enter an underscore. Alternatively, you can change this setting in the IPython configuration.
… for almost everything:

Displaying information about an object¶
With a question mark (?) you can display information about an object if, for example, there is a method multiply with the following docstring:
[7]:
import numpy as np
[8]:
np.mean?
Signature:
np.mean(
a,
axis=None,
dtype=None,
out=None,
keepdims=<no value>,
*,
where=<no value>,
)
Call signature: np.mean(*args, **kwargs)
Type: _ArrayFunctionDispatcher
String form: <function mean at 0x112944360>
File: ~/cusy/trn/jupyter-tutorial/uvenvs/py313/.venv/lib/python3.13/site-packages/numpy/_core/fromnumeric.py
Docstring:
Compute the arithmetic mean along the specified axis.
Returns the average of the array elements. The average is taken over
the flattened array by default, otherwise over the specified axis.
`float64` intermediate and return values are used for integer inputs.
…
Signature:
np.mean(
a,
axis=None,
dtype=None,
out=None,
keepdims=<no value>,
*,
where=<no value>,
)
Docstring:
Compute the arithmetic mean along the specified axis.
Returns the average of the array elements. The average is taken over
the flattened array by default, otherwise over the specified axis.
`float64` intermediate and return values are used for integer inputs.
Parameters
----------
a : array_like
Array containing numbers whose mean is desired. If `a` is not an
array, a conversion is attempted.
axis : None or int or tuple of ints, optional
Axis or axes along which the means are computed. The default is to
compute the mean of the flattened array.
.. versionadded:: 1.7.0
If this is a tuple of ints, a mean is performed over multiple axes,
instead of a single axis or all the axes as before.
dtype : data-type, optional
Type to use in computing the mean. For integer inputs, the default
is `float64`; for floating point inputs, it is the same as the
input dtype.
out : ndarray, optional
Alternate output array in which to place the result. The default
is ``None``; if provided, it must have the same shape as the
expected output, but the type will be cast if necessary.
See :ref:`ufuncs-output-type` for more details.
keepdims : bool, optional
If this is set to True, the axes which are reduced are left
in the result as dimensions with size one. With this option,
the result will broadcast correctly against the input array.
If the default value is passed, then `keepdims` will not be
passed through to the `mean` method of sub-classes of
`ndarray`, however any non-default value will be. If the
sub-class' method does not implement `keepdims` any
exceptions will be raised.
where : array_like of bool, optional
Elements to include in the mean. See `~numpy.ufunc.reduce` for details.
.. versionadded:: 1.20.0
Returns
-------
m : ndarray, see dtype parameter above
If `out=None`, returns a new array containing the mean values,
otherwise a reference to the output array is returned.
See Also
--------
average : Weighted average
std, var, nanmean, nanstd, nanvar
Notes
-----
The arithmetic mean is the sum of the elements along the axis divided
by the number of elements.
Note that for floating-point input, the mean is computed using the
same precision the input has. Depending on the input data, this can
cause the results to be inaccurate, especially for `float32` (see
example below). Specifying a higher-precision accumulator using the
`dtype` keyword can alleviate this issue.
By default, `float16` results are computed using `float32` intermediates
for extra precision.
Examples
--------
>>> a = np.array([[1, 2], [3, 4]])
>>> np.mean(a)
2.5
>>> np.mean(a, axis=0)
array([2., 3.])
>>> np.mean(a, axis=1)
array([1.5, 3.5])
In single precision, `mean` can be inaccurate:
>>> a = np.zeros((2, 512*512), dtype=np.float32)
>>> a[0, :] = 1.0
>>> a[1, :] = 0.1
>>> np.mean(a)
0.54999924
Computing the mean in float64 is more accurate:
>>> np.mean(a, dtype=np.float64)
0.55000000074505806 # may vary
Specifying a where argument:
>>> a = np.array([[5, 9, 13], [14, 10, 12], [11, 15, 19]])
>>> np.mean(a)
12.0
>>> np.mean(a, where=[[True], [False], [False]])
9.0
File: ~/spack/var/spack/environments/python-38/.spack-env/view/lib/python3.8/site-packages/numpy/core/fromnumeric.py
Type: function
By using ?? the source code of the function is also displayed, if this is possible:
[9]:
np.mean??
Signature:
np.mean(
a,
axis=None,
dtype=None,
out=None,
keepdims=<no value>,
*,
where=<no value>,
)
Call signature: np.mean(*args, **kwargs)
Type: _ArrayFunctionDispatcher
String form: <function mean at 0x112944360>
File: ~/cusy/trn/jupyter-tutorial/uvenvs/py313/.venv/lib/python3.13/site-packages/numpy/_core/fromnumeric.py
Source:
@array_function_dispatch(_mean_dispatcher)
def mean(a, axis=None, dtype=None, out=None, keepdims=np._NoValue, *,
where=np._NoValue):
"""
Compute the arithmetic mean along the specified axis.
Returns the average of the array elements. The average is taken over
the flattened array by default, otherwise over the specified axis.
`float64` intermediate and return values are used for integer inputs.
Parameters
----------
a : array_like
Array containing numbers whose mean is desired. If `a` is not an
array, a conversion is attempted.
axis : None or int or tuple of ints, optional
Axis or axes along which the means are computed. The default is to
compute the mean of the flattened array.
.. versionadded:: 1.7.0
If this is a tuple of ints, a mean is performed over multiple axes,
instead of a single axis or all the axes as before.
dtype : data-type, optional
Type to use in computing the mean. For integer inputs, the default
is `float64`; for floating point inputs, it is the same as the
input dtype.
out : ndarray, optional
Alternate output array in which to place the result. The default
is ``None``; if provided, it must have the same shape as the
expected output, but the type will be cast if necessary.
See :ref:`ufuncs-output-type` for more details.
See :ref:`ufuncs-output-type` for more details.
keepdims : bool, optional
If this is set to True, the axes which are reduced are left
in the result as dimensions with size one. With this option,
the result will broadcast correctly against the input array.
If the default value is passed, then `keepdims` will not be
passed through to the `mean` method of sub-classes of
`ndarray`, however any non-default value will be. If the
sub-class' method does not implement `keepdims` any
exceptions will be raised.
where : array_like of bool, optional
Elements to include in the mean. See `~numpy.ufunc.reduce` for details.
.. versionadded:: 1.20.0
Returns
-------
m : ndarray, see dtype parameter above
If `out=None`, returns a new array containing the mean values,
otherwise a reference to the output array is returned.
See Also
--------
average : Weighted average
std, var, nanmean, nanstd, nanvar
Notes
-----
The arithmetic mean is the sum of the elements along the axis divided
by the number of elements.
Note that for floating-point input, the mean is computed using the
same precision the input has. Depending on the input data, this can
cause the results to be inaccurate, especially for `float32` (see
example below). Specifying a higher-precision accumulator using the
`dtype` keyword can alleviate this issue.
By default, `float16` results are computed using `float32` intermediates
for extra precision.
Examples
--------
>>> a = np.array([[1, 2], [3, 4]])
>>> np.mean(a)
2.5
>>> np.mean(a, axis=0)
array([2., 3.])
>>> np.mean(a, axis=1)
array([1.5, 3.5])
In single precision, `mean` can be inaccurate:
>>> a = np.zeros((2, 512*512), dtype=np.float32)
>>> a[0, :] = 1.0
>>> a[1, :] = 0.1
>>> np.mean(a)
0.54999924
Computing the mean in float64 is more accurate:
>>> np.mean(a, dtype=np.float64)
0.55000000074505806 # may vary
Specifying a where argument:
>>> a = np.array([[5, 9, 13], [14, 10, 12], [11, 15, 19]])
>>> np.mean(a)
12.0
>>> np.mean(a, where=[[True], [False], [False]])
9.0
"""
kwargs = {}
if keepdims is not np._NoValue:
kwargs['keepdims'] = keepdims
if where is not np._NoValue:
kwargs['where'] = where
if type(a) is not mu.ndarray:
try:
mean = a.mean
except AttributeError:
pass
else:
return mean(axis=axis, dtype=dtype, out=out, **kwargs)
return _methods._mean(a, axis=axis, dtype=dtype,
out=out, **kwargs)
Class docstring:
Class to wrap functions with checks for __array_function__ overrides.
All arguments are required, and can only be passed by position.
Parameters
----------
dispatcher : function or None
The dispatcher function that returns a single sequence-like object
of all arguments relevant. It must have the same signature (except
the default values) as the actual implementation.
If ``None``, this is a ``like=`` dispatcher and the
``_ArrayFunctionDispatcher`` must be called with ``like`` as the
first (additional and positional) argument.
implementation : function
Function that implements the operation on NumPy arrays without
overrides. Arguments passed calling the ``_ArrayFunctionDispatcher``
will be forwarded to this (and the ``dispatcher``) as if using
``*args, **kwargs``.
Attributes
----------
_implementation : function
The original implementation passed in.
Signature:
np.mean(
a,
axis=None,
dtype=None,
out=None,
keepdims=<no value>,
*,
where=<no value>,
)
Source:
@array_function_dispatch(_mean_dispatcher)
def mean(a, axis=None, dtype=None, out=None, keepdims=np._NoValue, *,
where=np._NoValue):
"""
Compute the arithmetic mean along the specified axis.
Returns the average of the array elements. The average is taken over
the flattened array by default, otherwise over the specified axis.
`float64` intermediate and return values are used for integer inputs.
Parameters
----------
a : array_like
Array containing numbers whose mean is desired. If `a` is not an
array, a conversion is attempted.
axis : None or int or tuple of ints, optional
Axis or axes along which the means are computed. The default is to
compute the mean of the flattened array.
.. versionadded:: 1.7.0
If this is a tuple of ints, a mean is performed over multiple axes,
instead of a single axis or all the axes as before.
dtype : data-type, optional
Type to use in computing the mean. For integer inputs, the default
is `float64`; for floating point inputs, it is the same as the
input dtype.
out : ndarray, optional
Alternate output array in which to place the result. The default
is ``None``; if provided, it must have the same shape as the
expected output, but the type will be cast if necessary.
See :ref:`ufuncs-output-type` for more details.
keepdims : bool, optional
If this is set to True, the axes which are reduced are left
in the result as dimensions with size one. With this option,
the result will broadcast correctly against the input array.
If the default value is passed, then `keepdims` will not be
passed through to the `mean` method of sub-classes of
`ndarray`, however any non-default value will be. If the
sub-class' method does not implement `keepdims` any
exceptions will be raised.
where : array_like of bool, optional
Elements to include in the mean. See `~numpy.ufunc.reduce` for details.
.. versionadded:: 1.20.0
Returns
-------
m : ndarray, see dtype parameter above
If `out=None`, returns a new array containing the mean values,
otherwise a reference to the output array is returned.
See Also
--------
average : Weighted average
std, var, nanmean, nanstd, nanvar
Notes
-----
The arithmetic mean is the sum of the elements along the axis divided
by the number of elements.
Note that for floating-point input, the mean is computed using the
same precision the input has. Depending on the input data, this can
cause the results to be inaccurate, especially for `float32` (see
example below). Specifying a higher-precision accumulator using the
`dtype` keyword can alleviate this issue.
By default, `float16` results are computed using `float32` intermediates
for extra precision.
Examples
--------
>>> a = np.array([[1, 2], [3, 4]])
>>> np.mean(a)
2.5
>>> np.mean(a, axis=0)
array([2., 3.])
>>> np.mean(a, axis=1)
array([1.5, 3.5])
In single precision, `mean` can be inaccurate:
>>> a = np.zeros((2, 512*512), dtype=np.float32)
>>> a[0, :] = 1.0
>>> a[1, :] = 0.1
>>> np.mean(a)
0.54999924
Computing the mean in float64 is more accurate:
>>> np.mean(a, dtype=np.float64)
0.55000000074505806 # may vary
Specifying a where argument:
>>> a = np.array([[5, 9, 13], [14, 10, 12], [11, 15, 19]])
>>> np.mean(a)
12.0
>>> np.mean(a, where=[[True], [False], [False]])
9.0
"""
kwargs = {}
if keepdims is not np._NoValue:
kwargs['keepdims'] = keepdims
if where is not np._NoValue:
kwargs['where'] = where
if type(a) is not mu.ndarray:
try:
mean = a.mean
except AttributeError:
pass
else:
return mean(axis=axis, dtype=dtype, out=out, **kwargs)
return _methods._mean(a, axis=axis, dtype=dtype,
out=out, **kwargs)
File: ~/spack/var/spack/environments/python-38/.spack-env/view/lib/python3.8/site-packages/numpy/core/fromnumeric.py
Type: function
? can also be used to search in the IPython namespace. In doing so, a series of characters can be represented with the wildcard (*). For example, to get a list of all functions in the top-level NumPy namespace that contain mean:
[10]:
np.*mean*?
np.mean
np.nanmean